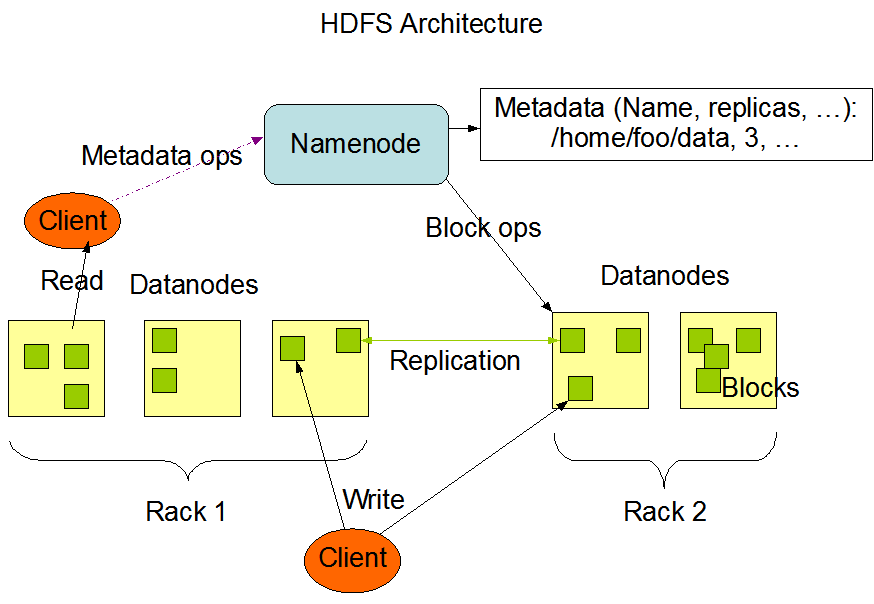
HDFS functionality:
Name node maintains the cluster live state by listening to the data nodes. For each specified interval of time, data node will send its status to name node. This mechanism is called heart beat. If name node does not receive heart beat from any data node, name node assumes that the data node is down and stop sending tasks to that data node.
Hadoop has different services to execute jobs and track the completion. Below are the some components.

(Image courtesy: dezyre.com)
Job:
A program posted to hadoop for execution is called a job.
Task:
A job will be sent to different slave nodes to process the data resided on data nodes. These instances of a job is called as task.
Job tracker:
Job tracker runs on Master node. Job tracker is responsible for gathering the status of each task from slave node and completion of the job.
Task tracker:
Task tracker runs in slave node and is responsible for getting the status of the tasks running on particular slave node, so that slave node will send these statuses to job tracker.
Initially client submits the program to process data to name node. Job tracker running on name node will get the metadata of the data which need to be processed. This metadata includes the data node and blocks information where the data is stored. Then the program will be posted to the slave nodes where the data is existing. The processes of the program running on several slave nodes are called as tasks.
Task tracker is responsible for maintaining the status of the tasks. Task tracker sends these statuses to job tracker. When all the tasks belong to a job is completed, job tracker will mark the job as completed.
Name node maintains the cluster live state by listening to the data nodes. For each specified interval of time, data node will send its status to name node. This mechanism is called heart beat. If name node does not receive heart beat from any data node, name node assumes that the data node is down and stop sending tasks to that data node.
Hadoop has different services to execute jobs and track the completion. Below are the some components.
(Image courtesy: dezyre.com)
Job:
A program posted to hadoop for execution is called a job.
Task:
A job will be sent to different slave nodes to process the data resided on data nodes. These instances of a job is called as task.
Job tracker:
Job tracker runs on Master node. Job tracker is responsible for gathering the status of each task from slave node and completion of the job.
Task tracker:
Task tracker runs in slave node and is responsible for getting the status of the tasks running on particular slave node, so that slave node will send these statuses to job tracker.
Initially client submits the program to process data to name node. Job tracker running on name node will get the metadata of the data which need to be processed. This metadata includes the data node and blocks information where the data is stored. Then the program will be posted to the slave nodes where the data is existing. The processes of the program running on several slave nodes are called as tasks.
Task tracker is responsible for maintaining the status of the tasks. Task tracker sends these statuses to job tracker. When all the tasks belong to a job is completed, job tracker will mark the job as completed.